New
Batch Program
Contents
This form is invoked from the menu New/Logic/Batch Program, and is used to generate a new batch program. It is also invoked from New/Conversion/Validate Data Definition to create a simple batch program to check a data definition. The generated program may need some editing: you’ll see several situations, even in these simple examples, where it is difficult or impossible to generate the program that you want but very easy to create something close enough to be easily edited to the correct Jazz statements.
The form looks like this: -
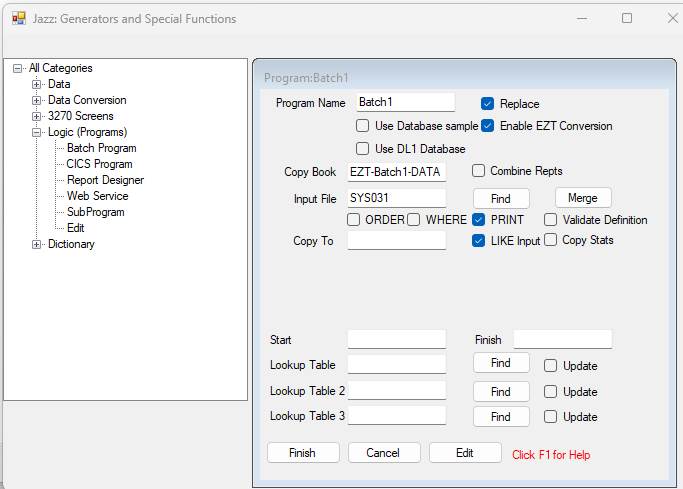
If [Merge] is clicked, a panel appears giving details of a second input file, allowing you to specify a batch program for sequential merging. See Merge Processing for details.
Recent changes have added
· Checkbox Combine Repts
· Checkbox Copy Stats. Previously these were always produced if you specified a Copy To file
· Merge panel, which appears if you click [Merge], allows you to specify the second input file, and the sequence keys relating them.
· Special handling for file NULL (relevant to Easytrieve conversion, for handling EZT JOB INPUT NULL)
· Support for DL/1 Databases
These new features may be omitted in the snapshots illustrating earlier features that haven’t changed.
Minimal
Options
If we give only the program name leaving the Input File blank and then click [Finish] then nothing but a PROGRAM statement is generated: -
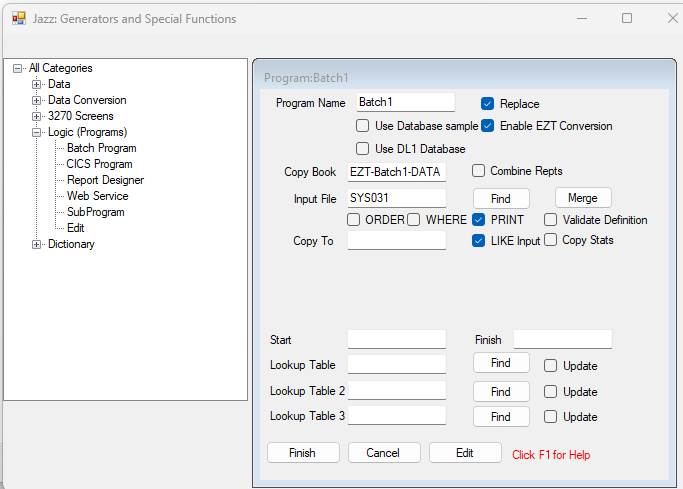
It is now up to us to write whatever program logic we want for this program.
If the program (“Batch1” in this example) already exists then a message and an [Edit] button appears. If we click [Edit] then the program is read into the workbench, as if we’d used File/Open.
Program Options
This section discusses the options from Program Name down to the Input File
Program Name
A valid program name must start with a letter, be no longer than 8 characters, and contain only letters and numbers (no special characters). Each name must be unique in your Jazz Programs folder.
Replace
If the program name is already used, you will get a message. Check this if you want your new program to replace it.
Use Database xxxxx
This checkbox appears if you have enabled SQL (Configure/SQL tab). Xxxx is the name of your SQL database (Sample in my examples).
Enable EZT Conversion
Check this if you’re creating a program for Easytrieve conversion. In summary,
· Option EZT will be added to the PROGRAM statement.
· The Jazz Workbench will have button [EZT Conv] to open the EZT Conversion Notepad, and [LProc] to create table load procedures
· Markers will be placed in the program so that the EZT Conversion notepad knows where to place logic.
See Easytrieve Conversion below for a more complete description.
Use DL1 Database
If this program is going to use DL/1, check this. Use Database xxxx must not be checked, and DL1 must be enabled (Configure/DL1 tab). If this is checked, a checkbox appears: set this to the PSBName (Program Specification Block) of your DL1 program: -
![]()
Copy Book
If Enable EZT Conversion was checked, this will be set to EZT-xxxxx-DATA, where xxxxx is the program name. This is the name that will have resulted from the Data/Import-from-Easytrieve database. You can edit this if you want to include some other copy book.
Combine Reports
Check this if the program is producing several reports, and you want them all to printed to the same report file. Check this and a textbox appears with the DDName of this report: -
![]()
If this option is checked, each report will be printed separately, with a page separator.
NB: your programs will be less efficient with this option compared to the default, which is to print each report directly using a unique DDName.
Input
File Options
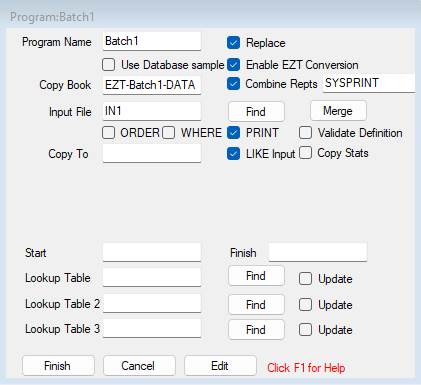
Most batch programs are basically a PROCESS loop reading an input file, which must be named here: -
![]()
If the textbox is blank, but the copy book is named, the input file will be set
to the name of the first file found in the copy book. If the file name is absent or incorrect, you
can use [Find] to look for one that is already known to your program.
We could leave Copy Book blank, or it might be unrelated to the Input file, in which case we enter the name of the input file. The input file can be a PSAM file (file type F, FB, V, VB, or U), VSAM or ESDS, a SQL table or view if Use Database xxxx is checked, or a DL1 root segment if Use DL1 Database is checked.
Here we’ve given the file name CustF, and left everything else to default: -
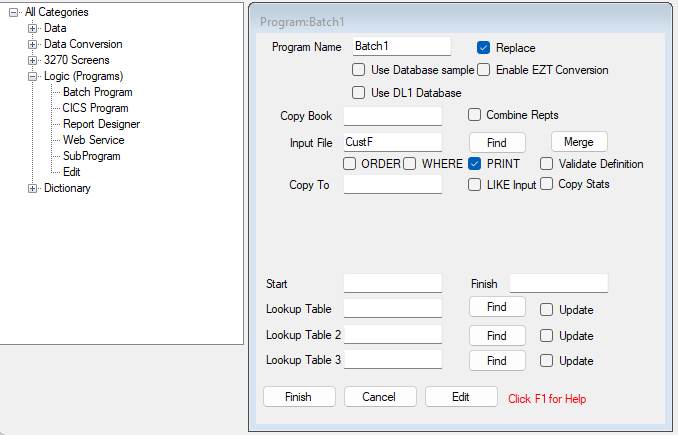
If we had not checked [ ] PRINT, then Jazz would have generated just the basic PROCESS loop: -

PRINT
Because we used PRINT, there is an intermediate stage that we don’t normally see, in which Jazz has generated
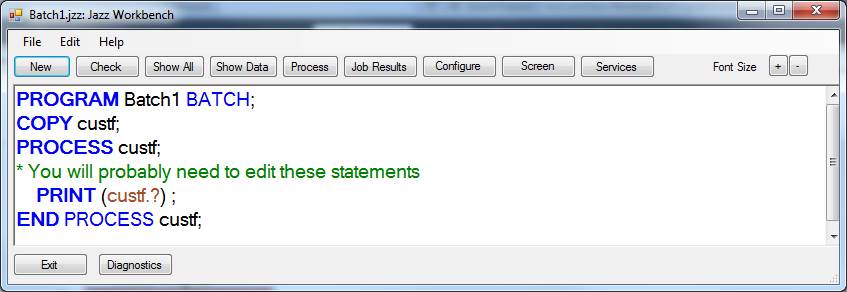
On recognising the “?” Jazz displays the Select Data form, from which we select the fields that we want in the left-to-right order that we want them to appear on the print line.

Having selected the fields we want for the PRINT, Jazz generates a program like this: -
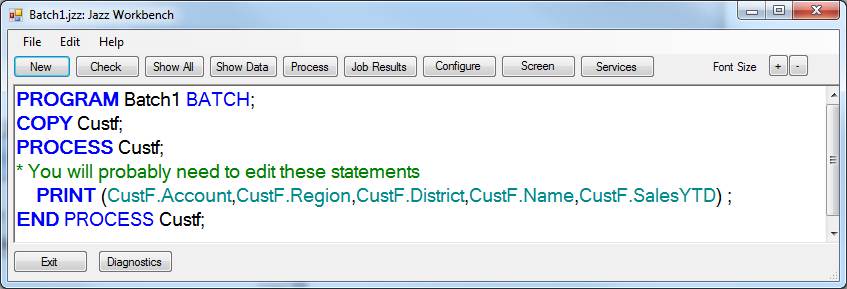
WHERE
In the example so far we will process every record from the input file, in the sequence in which they are read. If we check WHERE then Jazz adds WHERE (Custf.? = ?) to the PROCESS statement” =
PROCESS Custf WHERE (CustF.? = ?);
The queries (question marks) cause Jazz to display the Select Data form, just as they did in the example above. If we want a simple filter selection such as WHERE (CustF.Region = 3) then we can select Region from the first Select Data form, and then enter the value in the second: -

If we want a different type of comparison, such as WHERE (CustF.Region > 3) or WHERE (CustF.Region >= 3 AND CustF.Region <= 8), then generate a program with a very simple WHERE and edit it to be what you want.
Jazz then continues with another Select Data form from PRINT (Custf.?), and generates a program like this: -
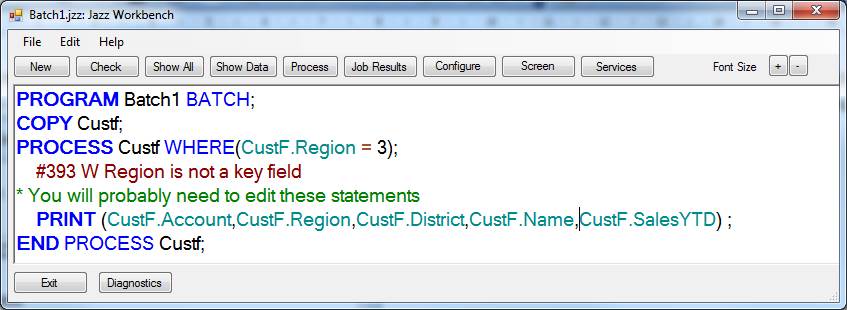
If there is a more complex selection, such as
WHERE(CustF.Region = 3 & CustF.District = 5);
then it’s easiest to leave [ ] WHERE unchecked, and add the WHERE clause later. If we select more than one field then syntax errors will result as the dialog doesn’t give us a way of entering the & operator, or giving a value like “3,5”, and so Jazz will generate an invalid PROCESS statement: -
ORDER
We check ORDER if we want the input file to be processed in a particular sequence. Jazz adds an ORDER option to the PROCESS statement: -
PROCESS Custf ORDER (CustF.?);
As above the “?” causes a query form to be displayed and we choose the sequencing fields from Custf: -

If we have left PRINT checked then not only will Jazz will have generated PRINT (Custf.?) as before, but also it will have added BREAK(Custf.?) to this statement. Choose the fields that you want to be control breaks, e.g. CustF.Region, Custf.District.
Validate File Definition
A new file definition, whether we directly wrote a Jazz definition or created a Jazz definition from COBOL, could be incorrect. For example, we might have described a field as CHAR(15) but actually the field is CHAR(20). All following fields will now be in the wrong position, 5 bytes earlier in the record. If we check Validate Definition then Jazz will generate a test program that will
1. Read the first record from the file
2. Print this record in FIELDTABLE format
3. Add ZERO to all DECIMAL and MONEY fields to attempt to force a data check.
Here’s an example of the output from

Even with an invalid record you should get something like this: -
Printed at 11 Sep 2016, 16:40:50 Report1 Page 1
* Field Name * LENGTH VALUE
CustF.Account : 6* 0
CustF.Region : 4* 2
CustF.District : 4* 9
CustF.Name : 15*JOSIAH,Josias *
CustF.SalesThisMonth: 10* $0.00
CustF.SalesYTD : 10* $0.00
CustF.Billingcycle : 13*006/June
CustF.DateCommenced : 10* *
However with an invalid record (as is this one from my test data) you’ll also see a dump produced when COBOL attempts to add zero to one of the DECIMAL fields. In this case SalesThisMonth and SalesYTD are not valid packed numbers, but have binary zero (LOW-VALUES in COBOL) value: -
1CEE3DMP V2 R1.0: Condition processing resulted in the unhandled condition. 09/11/16 4:40:51 PM Page: 1
ASID: 0030 Job ID: JOB08391 Job name: IBMUSERI Step name: GO UserID: IBMUSER
CEE3845I CEEDUMP Processing started.
Information for enclave BATCH1
Information for thread 8000000000000000
Traceback:
DSA Entry E Offset Statement Load Mod Program Unit Service Status
1 CEEHDSP +00004A4C CEEPLPKA CEEHDSP UI90017 Call
2 BATCH1 +0000069C BATCH1 BATCH1 Exception
DSA DSA Addr E Addr PU Addr PU Offset Comp Date Compile Attributes
1 19DE4620 050E7FA8 050E7FA8 +00004A4C 20150130 CEL
2 19DE4030 19C00000 19C00000 +0000069C 20160911 COBOLV5+ EBCDIC HFP
Condition Information for Active Routines
Condition Information for BATCH1 (DSA address 19DE4030)
CIB Address: 19DE4CF0
Current Condition:
CEE0198S The termination of a thread was signaled due to an unhandled condition.
Original Condition:
CEE3207S The system detected a data exception (System Completion Code=0C7).
Merge Processing
If [Merge] is clicked then the Merge Panel appears, and you can give details of the second input file, and the sequence keys that relate them: -

Click the [Skeys] button and a data selection dialog opens that allows you to select one or more fields from the corresponding file. You must select the same number of fields for File2 as you did for File1, and corresponding fields must be able to be compared.
A merge program will have a PROCESS statement like this: -
PROCESS FILE1 MERGE FILE2 SKEYS (FILE1.KEY1A,FILE2.KEY1B) COPY FILEOUT;
By naming an output file a sequential update program is generated: FILE1 is a “Masterfile” which is updated from FILE2 by creating a new copy, FILEOUT, which may include new records or omitted records based on the logic of the program.
For a sequential update to work, it is critical that the input files are in ascending sequence, and the first file should not have duplicate key values. If you check Check and/or Chk, logic will be inserted into the program to check this for the corresponding file, and a message will be displayed and the program will abort if records are out of sequence. If you check Sort the corresponding file will be sorted into ascending sequence of the SKEY field(s).
With merge processing the files must already be in the correct sequence, and you must process all of the records, so ORDER, WHERE, and Validate Definition are unchecked and disabled. Also, if you are creating an output file must have an identical format to the first input file, so LIKE Input is checked and disabled ensuring that this is so.
For more information on Merge Processing, see the Users’ Guide page Merge Processing.
NULL input files
If you give NULL as the name of the input file, then a program will be created that does not read any file. Another checkbox, Loop, appears: -
If Loop is checked, then the generated program structure will include a FOR loop: -
PROGRAM Test1 BATCH EZT;
COPY EZT-Test1-DATA;
*# Copy Files here ==>
FOR JZ2.IXNULL = 1 UNTIL JZ2.FLAGNull;
*#Copy Process logic here ==>
END FOR;
#783 W FOR loop may not terminate
*#Copy Routines here ==>
The loop obviously can’t be terminated by end-of-data, and you’re expected to write logic that will set JZ2.FLAGNull, or write some other logic to terminate the loop.
If Loop is unchecked, then the generated program is even simpler: -
PROGRAM Test1 BATCH EZT;
COPY EZT-Test1-DATA;
*# Copy Files here ==>
*#Copy Process logic here ==>
*#Copy Routines here ==>
NULL jobs are often associated with Easytrieve conversion.
Easytrieve Conversion
Recently (2022) features have been added to MANASYS Jazz to facilitate conversion of Easytrieve programs to Jazz (and then COBOL). If this is what you’re doing, then check Enable EZT Conversion. For example: -
When Enable EZT Conversion was checked, EZT-Batch1-DATA was entered into the copy book. This will have been created by the Data/Import from Easytrieve process, but if this doesn’t exist you can clear this textbox. The other effect of Enable EZT Conversion is to cause markers to be inserted into the generated Jazz program, so that further conversion steps know where to put definitions, process logic, following process loops, and routines.
If your program is producing multiple reports you may choose to check [ü] Combine Reports. If this is checked the ddname textbox appears with a default value [SYSPRINT]. The first report will be printed to SYSPRINT (or whatever you change it to), and other reports will be written to work files and copied to the first report on program termination, so that all the reports are produced in a single output file. This feature has been developed to allow users to mimic EZT behaviour, but it can be used whether or not [ ] Enable EZT Conversion is checked or not. For more information, see LRM/PROGRAM, look up REPTS option.
With the other options selected in this example the program will be a batch program reading records from Infile, and also, we have given values for Start and Finish. This creates the program below. Because Enable EZT Conversion was checked, the PROGRAM statement includes the option EZT, causing a button [EZT Conv] to appear, and the program to be generated with markers
*# Copy Files here ==>
*# Copy Process Logic here==>
*# Copy Routines (Procs) here;
These markers are used with [EZT Conv] as you convert your Easytrieve program to Jazz. This process is described in Easytrieve Conversion (jazzsoftware.co.nz).
Also, because routines were names with Start and Finish, PERFORM statements are generated around the PROCESS loop. The routines don’t exist yet so message #476 appears, but you’ll create these later.
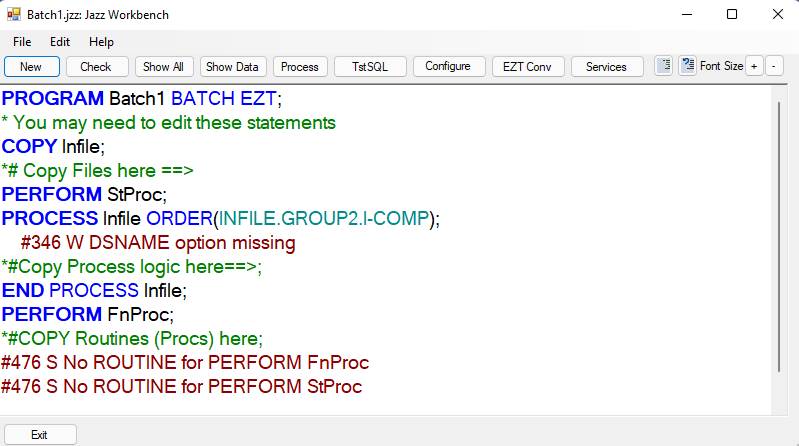
Start and Finish Routines
Whether or not Enable EZT Conversion is checked, you can name a routine to be performed before the PROCESS loop starts, and another when it terminates. The previous example shows this feature being used for both. PERFORM statements like those above will be inserted around the PROCESS loop if you use the Start and Finish textboxes. Alternatively, you can simply edit the generated program to insert them.
Copying and Reformatting Files
The third line of the New/Logic/Batch Program form contains the name of an output file, and check box labelled “Like”: -
![]()
By giving the name of an output file (“Out”), and checking “Like Input”, Jazz
1. Generates
the output file definition as
DEFINE Out
LIKE CustF;
With this definition it has exactly the same record layout and file type as Custf. It’s dataset name will be the same as Custf’s, except that where Custf used
DSNAME 'ibmuser.vsam.custf';
Out will replace “Custf” with “out” to use
DSNAME 'ibmuser.vsam.out';
If the LIKE file name cannot be found in the DSNAME value, even as part of a longer word, then 'O' is appended to the DSNAME value.
With the LIKE option the file is copied with the same record format. Of course WHERE and ORDER may select a subset of records, and/or write them out in another order.
2. Within the PROCESS loop Jazz will generate
out=CustF;
WRITE out;
If “LIKE Input” is not checked, then Jazz will check that a record layout named “Out” exists, and (if so) generate
1. COPY Out;
2.
out.*=CustF.*;
WRITE out;
With either option Jazz will also generate a record (working storage) to hold counts and sums. As a minimum this will contain counts of the records and read and written: -
DEFINE Copy-Stats DATA(
* Add any fields to be summed. For large files ensure fields have enough digits
Input-Count INTEGER,
Output-Count INTEGER);
INDEX is added to the PROCESS statement to count records read: -
PROCESS Custf INDEX Copy-Stats.Input-Count;
A statement to count the output records is generated (these two counts should be the same): -
Copy-Stats.Output-Count += 1;
* Add statements like 'Copy-Stats.Amount += out.Amount;' as relevant
A statement is generated after the PROCESS loop to print the accumulated statistics: -
PRINT (Copy-Stats.*) FIELDTABLE;
FIELDTABLE causes the PRINT to print a line for each field, with the field’s name and its value, instead of the more common layout in which fields are spread across the width of the page.
Look-up
Files
The New/Logic/Batch Program form allows you to specify up to three lookup files. In my test data I have a file called FR that can be looked up to return a Region Name corresponding to the number carried as Region in Custf. Here I’ve added this to the form: -
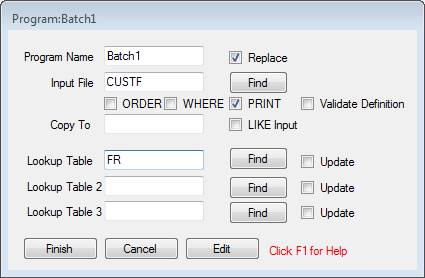
Now on clicking [Finish] to generate the program Jazz inserts
COPY FR;
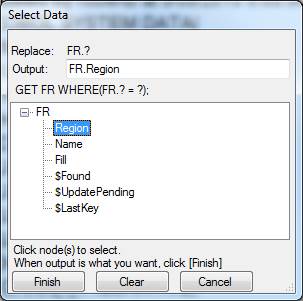
GET FR WHERE(FR.? = ?);
and the Select Data form is displayed to resolve these two queries: -
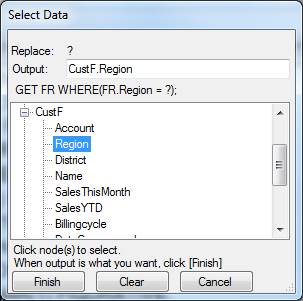
and then
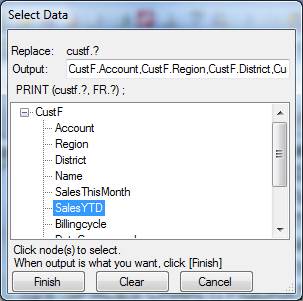
Also, the PRINT statement has “, FR.?” added to its data list, so that we now see Select Data twice for the PRINT statement: -
and
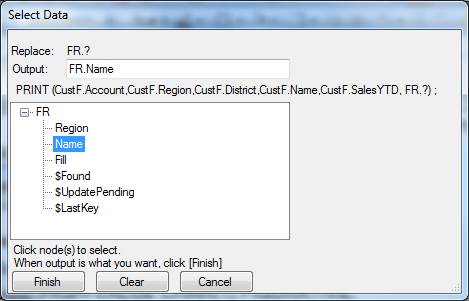
The generated program now includes these statements: -
PROGRAM Batch1 BATCH;
* You will probably need to edit these statements
COPY custf;
PROCESS custf;
COPY FR;
GET FR WHERE(FR.Region = CustF.Region);
PRINT (CustF.Account,CustF.Region,CustF.District,CustF.Name,CustF.SalesYTD, FR.Name) ;
END PROCESS custf;
· Up to three lookup files can be added from the form.
· With any of these you can check ‘UPDATE” if you want to update the look-up file.
· Further lookup files can be added by manually editing the generated program.
· You will probably want to edit the print statement to re-order the fields.
· If the lookup files have compound keys or complex keys, then you will need to edit the WHERE clause.