Using
Jazz with DL1
Configuring
MANASYS Jazz for DL1
Converting
Easytrieve DL1 Definitions to Jazz
To use DL1
with Jazz requires Jazz Version 3.17.2.310 or later.
Introduction – what is DL1?
DL1 (or DL/1
or DL/I or DLI) is a hierarchical database system, part of IMS (Information
Management System), developed in 1966 by IBM, Rockwell, and Caterpillar for the
Apollo program to send a man to the moon. It started the database management
system revolution, and although it has been superseded by relational databases
such as DB2 and others, it still exists in legacy IBM environments. From Build #310 MANASYS Jazz users will be
able to convert Easytrieve programs using DL1 to Jazz, which will create COBOL
to read and update DL1 databases. As
with SQL, Jazz attempts to minimize the differences between DL1 and other data,
for example using PROCESS and GET to read [and update] data, and WRITE to
create new data. (DLI stands for “Data Language Interface”, but all programmers
I knew that worked with it called it “D L one”, not “D L eye”, so I’ve used DL1
in Jazz).
Although
MANASYS minimizes differences, to work with Jazz and DL1 successfully you will
need to understand how a hierarchical database works so that you can work with
it. DL1 is very different to relational
databases. Three key points: -
1.
DL1
is designed to be used from a program, written in languages like Assembler,
COBOL, PL/I, Easytrieve, etc. It has no
intrinsic query language. It cannot be
used on its own, but relies on an application program to read and write
records, handling execution sequence and display.
2.
Data
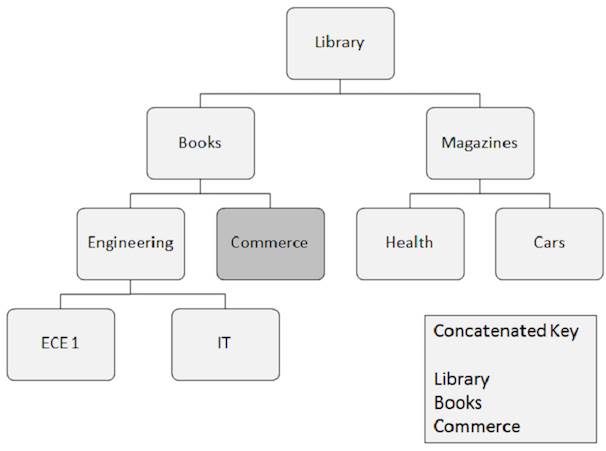
is arranged hierarchically, as shown in IMS DB -
Structure (tutorialspoint.com).
Each unit – “Segment” in DL1, “Record” in COBOL and Jazz – is the
smallest unit that can be read or written, and will contain 1 or more
fields. This diagram, from IMS DB -
DL/I Processing (tutorialspoint.com), shows an example. Records can be read sequentially or
directly. The root segment (Library) can
be read directly by its key, lower level segments are
read with the concatenated key of their path, as shown here for Commerce.
3.
DL1
depends on the application language (COBOL, Easytrieve, etc) to define the
fields within the database. We are used
to modern databases like DB2, Oracle, etc., containing tables and columns, with
the columns (fields) giving us a detailed definition of the database
structure. This allows query languages
like SQL to interpret statements like (SELECT Name, City FROM Library WHERE
City IN (SELECT City From CityList
where CityList.Country = “USA”). A DL1 database however may contain no more
information about a record than its name, length, and key length, and its
relationship to other segments.
For example, the only information recorded about the Library
record is that the record length and key length are both 10 bytes. Whether these 10 bytes contain 1 or several
fields known to COBOL (etc) is not defined.
In order to use Jazz with DL1 it will be necessary to combine the
information in the database with information from a COBOL or Easytrieve
program, as described below in Defining our DL1
Database.
Compared to
DB2 and other relational databases DL1 operations are very fast, but it is up
to the application program to define the navigation necessary to get to the
data you want. With its defined
hierarchy DL1 is less flexible than relational databases, and DL1 databases are
complex to implement and difficult to manage.
In the 21st century I doubt that anybody would choose to use
DL1 for a new database application, but it was a good idea in 1966. Remember, it was designed for a world in
which computer memory cost about $2.5 billion per megabyte (current price about
$2), and was important in the Apollo Program that got men to the moon in
1969. It wasn’t until about 1980 that
computers became powerful enough and cheap enough that relational databases,
first proposed in 1974, started to become viable.
“DL/1”,
“DL1”, “DLI”, “IMS DC”, and “IMS” are all synonyms as far as we are
concerned. We need not be concerned with
their differences, or with the differences between various versions, we are
only concerned with how you use MANASYS Jazz with DL1. For an introduction to DL1 see https://www.tutorialspoint.com/ims_db/index.htm. MANASYS Jazz does not support IMS-DC,
communication software that, like CICS, manages on line programs.
Configuring
MANASYS Jazz for DL1
Before you
can use DL1 with MANASYS Jazz, you must enable DL/I support. DL1 support is
still under development and should only be used by our development partners at
this stage.
Open the
Jazz workbench, click [Configure], and click the DL1 tab. Check Enable DL1.
The form
defines the local and mainframe libraries that you’ll use for general DL1
programming. However, if you are converting Easytrieve Programs to Jazz, for
later conversion to COBOL, the local libraries are not used as the EZT program
contains all the information that will be needed, and this information is
directly available to the Jazz program with
Data/Import From Easytrieve.
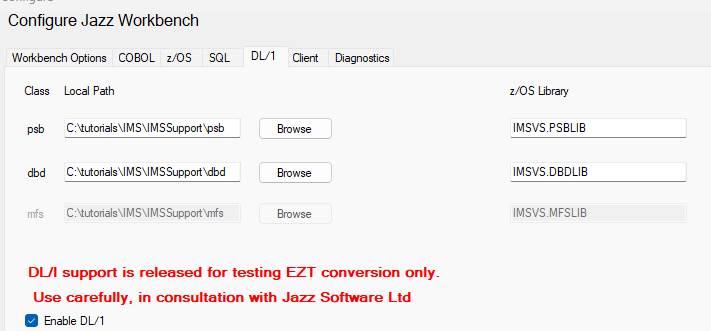
There are 3
rows of textboxes. The psb (1st) and dbd (2nd)
rows are particularly important. PSB
means Program Specification Block, DBD means Database Descriptor. The z/OS Library values must be defined as
these will be used to create the JCL used when jobs are submitted to compile
and run COBOL programs using DL1. However if you are using Import-from-Easytrieve to get data
definitions, the local path values are largely ignored.
The 3rd row is disabled. This row contains information that would be needed if you were going to generate classical CICS programs using IMS-DC, communication software that performs the same functions as CICS, although with different program interface. There are no current plans to implement IMS-DC support in MANASYS Jazz, but the 3rd row is defined in case this should change.
Most likely
you will set these values by clicking [Browse] and navigating to the relevant
folder. The line message will tell you
if they’ve been found. Also, you’ll get
a warning message “Not end with xxx” if the folder name doesn’t end with the
expected text, for example
![]()
If MANASYS
is configured to work directly with z/OS (see Configure/Workbench tab) then the
local folders will need to contain copies of information held in the
corresponding z/OS library. When a
particular object is needed but it’s not found, a dialog will help you to
download it from the z/OS library.
If MANASYS
is configured to work with Micro Focus COBOL then the local folders are shared
between MANASYS Jazz where COBOL is generated, and Micro Focus where the COBOL
is compiled. If the folders don’t exist
and you create them from this dialog, then they will be available to the
project but they won’t be visible in Solution Explorer. You can however create the folder with
·
In
Solution Explorer, right-click your project, e.g. TstSQL
here
·
Click
Add/New Folder from the context menu
·
Give
the folder the name that you want, e.g. psb
This will
create the folder within the current folder (in this case TstSQL),
and also make it visible in Solution Explorer.
It is recommended that you do this first in your COBOL project, enabling
DL1 and making the folders visible, and then locate these folders when you
configure MANASYS to support DL1. It
doesn’t matter whether they are part of the Jazz
project, it will find what it wants from the folders anyway, but they need to
be part of the COBOL project so that Build Project includes them, allowing the
compiled COBOL program to run.
Converting Easytrieve DL1
Definitions to Jazz
As always, the first part of any EZT conversion is to use the dialog New/Data/Import from Easytrieve to create a copy book containing all of the data definitions used by the EZT program. If our program is called ADL1PGM, then a copy book named EZT-ADL1PGM-DATA will be created containing all of the data definitions required by the program in Jazz format. Like any other EZT-converted definition, it will contain information for sequential and VSAM files, and their record definitions, plus working data definitions from this program. EZT-ADL1PGM-DATA will also include a definition of PSBNAME with data type PCB, and definitions for each segment used by this program with type DL1. These definitions are all found in the EZT program, either directly or in EZT macros.
The definition of PSBNAME will look something like this
DEFINE PSBNAME PCB DATA(
GROUP1 GROUP,
PSBNAME-DBD
CHAR(8), [DB-Name]
PSBNAME-LEV
CHAR(2),
PSBNAME-STC
CHAR(2), [Status-Code]
PSBNAME-PRO
CHAR(4), [Processing-Option]
FILLER
CHAR(4),
PSBNAME-SEG
CHAR(8), [Segment-Name]
PSBNAME-KFL
INTEGER, [Lth of KFBA]
PSBNAME-NSS
INTEGER,
PSBNAME-KFA CHAR(254), [KFBA (key feedback area, variable!)
End GROUP);
For each DL1 segment there will be a
definition created looking like this: -
DEFINE V05P1A DL1 DATA(
SEGMENT CHAR(350),
GROUP1 GROUP REDEFINES V05P1A.SEGMENT,
Field Format ,
...
End GROUP,
GROUP2 GROUP REDEFINES V05P1A.SEGMENT,
…
End GROUP,
GROUP3 GROUP REDEFINES V05P1A.SEGMENT,
…
V05P1A is the root segment of this
database, like the Library segment in the diagram above. V01P2A is a second-level segment,
like Books. Such segments are defined
like V01P1A, but include PARENT naming their
parent segment. For example,
DEFINE V05P2A DL1 PARENT V05P1A DATA(
SEGMENT CHAR(300),
GROUP1 GROUP REDEFINES V05P2A.SEGMENT,
This allows MANASYS to ensure the validity of Jazz statements and generated COBOL statements, and to know
when direct access to any is possible or when access is only possible for
records that are related to a parent segment.
Creating a
Jazz DL1 Program
Like any other batch program, once we’ve
defined the main copybooks defining the program’s input data, we use the
New/Logic/Batch dialog to start creating its logic. Our program uses DL1 so we check Use DL1
Database, and give the name of the PSB, in this example PSBNAME. Other details are like other new
programs. The input file might be a DL1
root segment, or an unrelated file as here: -
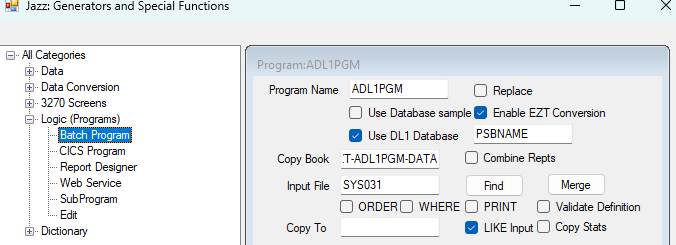
This results in a Jazz
program that starts like this: -
PROGRAM ADL1PGM BATCH DATABASE PSBNAME DL1 EZT;
COPY JZDL1 JAZZ;
*# SSA's go here
==>
COPY EZT-ADL1PGM-DATA;
*# Copy Files here ==>
#762 W COPY code produces 1 W and 0 I messages
PROCESS SYS031 ORDER(NULL) TALLY SID(22);
#785 W File
will be processed in its natural order
*#Copy Process logic here ==>
END PROCESS SYS031;
*#Copy Next Process here ==>
*#Copy Routines here ==>
At this stage we could [Process]
this program and compile the COBOL. Of
course, it wouldn’t actually do anything except read file SYS031 to end, but at
least it would have the correct format for a DL1 COBOL program, with PSBNAME
generated into the linkage section and the procedure division starting with
011780 PROCEDURE DIVISION
USING PSBNAME.
011790 ENTRY 'DLITCBL' USING PSBNAME.
Now we convert the logic of our EZT program into program ADL1PGM using the Easytrieve Conversion Notepad to convert the logic into Jazz. This process is described in https://www.jazzsoftware.co.nz/Docs/JazzUGEZTLogic2.htm. The only section of this that is specific to DL1 is EZT_DLI_Statements.
Parking
Build #310 has concentrated entirely on programs that have resulted from EZT conversion, a later release will enhance it to allow for general use of Jazz for new DL1 programs. You can ignore the following notes: they are my own draft notes of how Jazz may look with further development. As with SQL, the plan is to make it possible to write programs using PROCESS, GET, etc used in essentially the same way whatever the organization of the data. For example, you’ll be able to write
GET DL1Seg WHERE (condition) UPDATE;
…
END
GET DL1Seg UPDATE;
MANASYS Jazz would generate all the SSA’s needed for this to work, or report errors if the statements are invalid. However, this is a significant development, and for EZT conversion (the initial priority) it is unnecessary as the logic is already present in the EZT program and it makes no sense to convert the DLI statements into another format and then develop logic to convert this other format back to something closer to the original EZT logic. The plan above is only worth doing if there is a real need to write new Jazz DL1 programs.
Defining the DL1 Database
Once MANASYS is configured to work with DL1, you can write Jazz programs that access DL1 by starting them with
something like
PROGRAM DL1Tst1 BATCH DATABASE DEMO001T DL1;
DEMO001T is the name of a PSB (Program Specification Block) describing
your DL1 database. From this PROGRAM statement MANASYS knows
1.
to
retrieve the PSB and related DBD (Database Descriptor),
2.
Function
and Return Codes needed to access DL1, and
3.
to
generate a PCB to manage communication between COBOL and DL1.
This defines the basic DL1 environment, but we still must define the
records that we’ll be accessing, just as we did with
PROGRAM Aanexmpl
BATCH;
COPY IN1;
so Jazz inserts a copy statement
COPY JZ- DEMO001T;
to contain
the record definitions.
JZ-DEMO001T
won’t exist initially, so we have to create it.
We can do this with Import-From-COBOL or Import-From-Easytrieve, or by
creating the definition using the Jazz Workbench starting with a blank screen. The last option is the hardest as we
have to be careful to get all the record descriptions exactly correct and make
sure that the particular rules of the data type have been followed. It’s much easier to create the definitions
starting with COBOL or EZT, and then enhance this definition with Jazz properties like RANGE, CODE, etc to make it more powerful.
DL1 records
(segments) are defined with type DL1, otherwise they are the same as any other
Jazz data definition: -
DEFINE Library DL1 DATA(
NAME CHAR(20));
Library is the
root segment of the database illustrated above.
For other segments, the definition contains a Parent property, e.g.
DEFINE Books DL1 PARENT Library DATA(
…
Such record
definitions are invalid if they are used within a program that does not specify
DATABASE Psbname DL1, or if Library and Books are not
within the list of record names contained in the PSB.
DL1 Records from COBOL
If you have
a DL1 program that processes DL1 with a PSB, then you can prepare the
definition starting with Import from COBOL, provided that MANASYS Jazz is
configured for DL1, and the PSB and related DBD are available in the local PSB
and DBD folders. Then use Import from
COBOL to convert your COBOL program, with the DL1 panel naming the PSB. This will cause the entire program to be
scanned for conversion, but only the records named as segments in the PSB to be
processed.
Input and Output
Records in
a DL1 database are processed with the same statements as VSAM, SQL, and other file types: PROCESS, GET, WRITE, UPDATE, and DELETE.
In some cases there are some extra options and
a little more flexibility, but generally there is as little difference as
possible. Users will have to understand
the DL1 database structure, and the sequence of operations necessary to
navigate around the database, to use them successfully with DL1.
PROCESS
As usual, PROCESS /END PROCESS is used
to read records sequentially. With DL1 the first PROCESS must read the top record of a
hierarchy (Library), within this there can be further levels of PROCESS, but they must specify lower-level
records in hierarchical sequence. For
example, to print a list of Books about Commerce,
PROCESS
Library;
PROCESS
Books;
PROCESS Commerce;
PRINT (Library.name, Books.SectionName, Commerce.Title);
END PROCESS Commerce;
END PROCESS Books;
END PROCESS Library;
Notes:
1.
The
outer PROCESS
statement may have an ORDER
option, but ORDER will
probably not be permitted at lower hierarchy levels. If you want to present
lower-level records in a different sequence then it might be necessary to write
the data to a work file which can then be re-processed in the sequence that you
want. But see #4
2.
Inner
PROCESS
statements read records within the hierarchy, for example PROCESS Books; only reads Books records for
the current Library.
3.
Each
PROCESS
statement may have a WHERE condition, which may reference both key and non-key fields. The WHERE condition is a filter: like reading a
sequential file, all records are read but those that do not meet the WHERE
criteria are discarded. As with all
other file types, you can use SQL operators BETWEEN, IN, and LIKE (or ~ meaning LIKE), as comparison operators.
4.
It
may be possible to combine several hierarchy levels, for example
PROCESS
Library, Books, Commerce;
PRINT (Library.name, Books.SectionName, Commerce.Title);
END PROCESS Library,
Books, Commerce;
If this is supported and the first
record named is the root segment, it should be possible to allow ORDER.
GET
GET is
intended for situations where you want to read one particular record, and
requires an SSA, KEY or WHERE option to specify which record you want. SSA is always used when GET is generated by
EZT conversion, and it can be assumed that the SSA has the correct format.
Like VSAM, a DL1 GET that
is ambiguous returns the first record.
In CICS
programs GET may
return the first of many records, with your program using PF7/8 paging to get
the previous and next record. It is not
defined which record is “First”.
WRITE, UPDATE, and DELETE
If the PROCESS or GET statement uses SSA, then these are explicitly written and may require that the PSB status code is checked. When UPDATE options on PROCESS or GET statements are used to cause the record to be updated when the next record is retrieved, or the program finishes, they will be implicit and necessary status code checking will be automatically included.